 Notes techniques concernant la version 3.5 de PMBHiérarchie de section : Les recherches dans PMB : principes théoriques et applications > Comment fonctionne le système de recherche jusqu'à la version 3.4
Notes techniques concernant la version 3.5 de PMBHiérarchie de section : Les recherches dans PMB : principes théoriques et applications > Comment fonctionne le système de recherche jusqu'à la version 3.4Comment fonctionne le système de recherche jusqu'à la version 3.4
La recherche dans PMB sous-entend la recherche booléenne.
Principe de base d'indexation des champs
Pour chaque champ cherchable en booléen, PMB construit deux index utilisés pour la recherche :
Un index dit nettoyé
Un index dit exact
L'index nettoyé comporte l'ensemble des mots (ou nombres) du champ en question après les traitements suivants :
Remplacement des caractères spéciaux (tout ce qui n'est pas chiffre ou lettre) par des espaces.
Remplacement des diacritiques (accents, cédilles) par les lettres équivalentes sans diacritiques.
Passage systématique en minuscules
Suppression des mots vides et des espaces en multiples.
Cet index va servir à la recherche d'un mot (ou plusieurs), indépendamment de la phrase à laquelle il appartient.
Phrase de départ |
|
Remplacement des caractères spéciaux (tout ce qui n'est pas chiffre ou lettre) par des espaces |
|
Remplacement des diacritiques (accents, cédilles) par les lettres équivalentes sans diacritiques |
|
Passage systématique en minuscules |
|
Suppression des mots vides |
|
La recherche d'un mot pourra donc porter sur l'un des mots restant. Évidemment, lors d'une recherche, la phrase de recherche est nettoyée de la même manière et l'on compare les mots tapés dans la recherche et les mots de l'index.
L'index exact est la valeur d'origine du champ, non nettoyée. L'index exact est souvent le même que le champ lui même (on ne crée d'ailleurs pas forcément un champ particulier).
L'index exact sert à rechercher un extrait tel quel du champ (le caractère "au début et à la fin d'un terme de recherche permet cela dans PMB).
Phrase de départ |
|
Index exact |
|
La plupart de temps dans la base de données, l'index exact est une agrégation de plusieurs champs, il y a donc recopie de ces valeurs mises bout-à-bout dans un champ supplémentaire de la même table ou une lecture directe des champs concernés. L'index nettoyé est toujours le nettoyage de l'index exact. Il est aussi stocké dans un champ supplémentaire dans la même table.
Index | Table | Champ(s) index exact | Agrégé des champs | Champ index nettoyé |
|---|---|---|---|---|
Titre d'une notice | notices | index_wew | tit1, tit2, tit3, tit4 | index_sew |
Indexation d'un auteur | authors | author_name + autor_rejete | Lecture directe des champs | index_author |
Pour la recherche tous les champs, deux index spéciaux sont créés dans une table adéquate qui est une agrégation de tous les champs recherchables. Ce sont les champs infos_global (index exact) et index_infos_global (index nettoyé) de la table notices_global_index.
Toutes les indexations sont réalisées par PMB à l'enregistrement de chaque notice/autorité.
Analyse de la saisie
Lors d'une recherche, l'expression recherchée est analysée et traduite en requêtes SQL sur les index détaillés dans la partie précédente. Cette analyse se fait en plusieurs étapes.
Détection des opérateurs
L'expression saisie est découpée en termes selon les opérateurs qui ont étés saisis : elle est séparée en termes sur les caractères espace (l'espace représente l'opérateur par défaut), +, -, (), "
Traitement des termes
Chaque terme est analysé à son tour :
Si c'est un mot simple (pas de caractère ~, ^, ( ou " devant) : on le nettoie (suppression des caractères spéciaux, suppression des diacritiques, mise en minuscules). Si la suppression des caractères spéciaux a donné plusieurs mots, on traite chaque mot (par exemple : l'argenté devient deux mots : l et argente, ou saint-glinglin devient saint ou glinglin). On supprime le(s) mot(s) vide(s). S'il ne reste qu'un mot vide, on ne tient pas compte du terme : il est rejeté.
Si c'est un mot simple avec un caractère modificateur ~ (non) ou ^ (commence par) devant, on retient la signification du modificateur et on nettoie le mot
Si le terme commence et fini par le caractère ", on le garde tel quel comme expression exacte
Si le terme commence par ( et finit par ) , on analyse ce qui est contenu dans les parenthèses comme une nouvelle expression à part entière, que l'on analyse à nouveau.
Le caractère * est remplacé par le caractère % dans les termes, car c'est le caractère de troncature de MySQL. Le caractère % n'est pas considéré comme caractère spécial et n'est donc pas nettoyé.
Composition d'un arbre représentant l'expression
Chaque terme est associée à l'opérateur (et, ou ou sauf) qui le combine avec le terme précédent, ainsi qu'aux modificateurs (non, commence par). On les liste dans l'ordre d'apparition, si un terme est une expression (il était dans des parenthèses), il devient une "sous-branche" de la liste. Cette sous-branche est elle même une représentation en liste de l'expression. Chaque sous-branche peut elle-même être composée d'autres sous-branches.
L'ensemble des listes et des branches s'appelle un arbre : c'est la représentation symbolique de l'expression recherchée.
Expression d'origine : Le "chat botté" (2012 - (bois + l'orée))
Traduction : recherche de chat botté ou des individus vus en 2012, sauf ceux qui ont étés vus à l'orée du bois
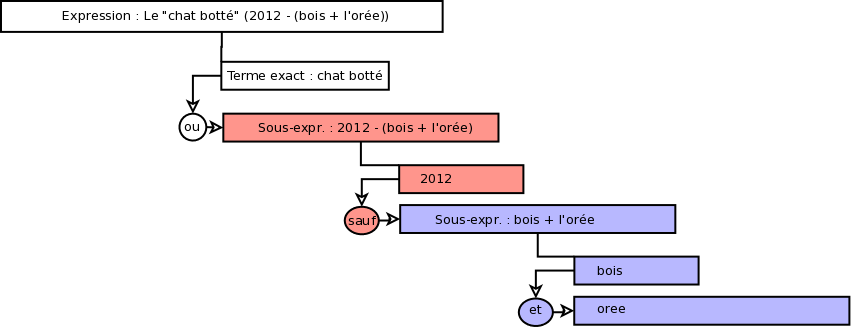
Construction de la recherche à partir de l'analyse
L'arbre est parcouru dans l'ordre de ses termes.
Si le terme est un mot simple, on effectue la recherche dans l'index nettoyé
Si le terme est une branche, on évalue cette branche comme une recherche autonome.
Si le terme est une expression exacte, on effectue la recherche dans l'index non nettoyé
Le résultat de recherche de chaque terme est combiné au précédent selon l'opérateur.
Appliquons l'arbre précédent à la recherche sur titre. Le premier terme exact "chat botté" sera recherché dans l'index non nettoyé du titre (index_wew de la table notices). Les identifiants des notices trouvées sont mémorisées.
Ensuite, le terme 2012 sera recherché dans l'index nettoyé (index_sew de la table notices) les identifiants des notices trouvées sont mémorisées.
Ensuite le terme bois sera recherché dans l'index nettoyé, puis le terme oree dans le même index.
Les identifiants des notices communes (opérateur et : les notices qui contiennent l'un et l'autre) aux termes bois et oree sont supprimées du résultat de recherche de 2012, puis les identifiants restants sont ajoutés (opérateur ou : l'un ou l'autre) aux identifiants de notices issus de la recherche exacte "chat botté".
MySQL supporte très bien les opérateurs et (and), ou (or) et sauf (and not) dans les conditions. L'arbre est donc traduit en une seule requête SQL. La recherche dans les index est effectuée avec 2 troncatures à gauche et à droite.
La recherche va se traduire par : "les notices qui ont un index qui contient quelque chose, un espace, le mot, un espace, quelque chose". Soit en SQL : like '% mot %'. Le mot peut contenir lui même une ou plusieurs troncatures.
Pour que la recherche fonctionne aussi sur le premier et le dernier mot de l'index nettoyé, on ajoute systématiquement un espace au début et à la fin de l'index.
La recherche va se traduire par : "les notices qui ont un index exact qui contient quelque chose, l'expression exacte, quelque chose". Soit en SQL : like '%expression exacte%'. L'expression exacte peut contenir elle-même des troncatures.
L'abre précédent devient alors en SQL :
select notice_id from notices where index_wew like '%chat botté%' or (index_sew like '% 2012 %' and not(index_sew like '% bois %' and index_sew like '% oree %'))
Pertinence et pondération
Pertinence
Le calcul de la pertinence est simple à réaliser. Il consiste à compter le nombre de termes présents dans le champ de recherche pour chaque notice. On ne retient bien sûr que les termes mots ou expressions exactes, quelque soit la profondeur dans l'arbre, à condition que le terme soit positif.
Un terme est dit positif s'il peut ou doit être présent dans le champ de recherche pour que la notice soit prise en compte. A contrario, un terme est dit négatif si la présence de ce terme dans le champ de recherche interdit de prendre en compte la notice.
Dans l'exemple précédent bois et oree sont des termes négatifs : ils ne doivent pas être présents pour qu'une notice réponde à l'expression 2012 - (bois + l'orée) : 2012 sauf bois et oree. Les termes positifs sont dans notre exemple "chat botté" et 2012.
Après repérage des termes positifs, on peut calculer la pertinence directement en SQL : l'expression SQL index_sew like '% 2012 %' vaut 1 si elle est vrai et 0 si elle est fausse. Dans notre exemple, la pertinence vaut index_wew like '%chat botté%'+index_sew like '% 2012 %'.
La requête finale dans notre exemple de recherche Le "chat botté" (2012 - (bois + l'orée)) sur le champ titre est donc :
select notice_id, index_wew like '%chat botté%'+index_sew like '% 2012 %' as pert from notices where index_wew like '%chat botté%' or (index_sew like '% 2012 %' and not(index_sew like '% bois %' and index_sew like '% oree %'))
La requête renvoie deux colonnes : numéro de notice et la pertinence associée (ici comprise entre 1 et 2). Le résultat sera trié par pertinence décroissante.
Pondération
Certains termes peuvent être pondérés dans le calcul de la pertinence. C'est à dire que l'on multiplie par un nombre inférieur à 1 s'il on veut qu'il aie moins d'importance et par un nombre supérieur à 1 si l'on veut qu'il aie plus d'importance.
La pondération est appliquée à un terme supplémentaire que l'on ajoute systématiquement dans le calcul de la pertinence : les notices qui ont le champ de recherche qui commence par exactement l'expression recherchée. La pondération est de 0,2.
Cela permet de faire remonter en premier les notices dont le champ de recherche ressemble le plus à l'expression saisie (et notamment les notices qui ont le titre exact).
Ce terme n'est ajouté qu'à la pertinence et non aux conditions de recherche SQL.
Pour réaliser cette pondération, on ajoute le terme exact commence par "l'expression recherchée" à l'arbre issu de l'analyse. On ajoute un indicateur pour préciser que le terme ne doit être pris en compte que pour le calcul de la pertinence.
Dans notre exemple, on ajoute à la pertinence le terme SQL : (index_wew like '%Le "chat botté" (2012 - (bois + l'orée))%')*0.2 (qui n'a pas beaucoup de sens !)
Dans le cas de la recherche tous les champs, on ajoute à la pertinence de la recherche tous les champs la même pertinence calculée sur le titre, pondérée à 0,2. Ainsi, les notices qui ont dans le titre des termes recherchés sont mises en avant.
- Un nouveau système de recherche
- Les recherches dans PMB : principes théoriques et applications
- Comment fonctionne le système de recherche jusqu'à la version 3.4
- Principales limitations de la recherche jusqu'en 3.4
- Comment fonctionne le nouveau système de recherche à partir de la version 3.5
- Avantages et inconvénients de la nouvelle recherche
- Implications de la nouvelle recherche dans PMB 3.5
- Annexe : liste des codes champ/sous-champ pour l'indexation
