 Notes techniques concernant la version 3.5 de PMBHiérarchie de section : Les recherches dans PMB : principes théoriques et applications > Comment fonctionne le nouveau système de recherche à partir de la version 3.5
Notes techniques concernant la version 3.5 de PMBHiérarchie de section : Les recherches dans PMB : principes théoriques et applications > Comment fonctionne le nouveau système de recherche à partir de la version 3.5Comment fonctionne le nouveau système de recherche à partir de la version 3.5
Principe de base de l'indexation des champs
De la même manière que pour l'ancienne recherche, on garde les notions d'index nettoyé et d'index exact. La grande différence est que l'ensemble des index de toutes les notices sont dans une table unique.
Structure de la table index nettoyée
Chaque champ d'une notice est associé à un code et un sous code (comme en unimarc !). Chaque champ de chaque notice est nettoyé :
Remplacement des caractères spéciaux (tout ce qui n'est pas chiffre ou lettre) par des espaces.
Remplacement des diacritiques (accents, cédilles) par les lettres équivalentes sans diacritiques.
Passage systématique en minuscules
Suppression des mots vides et des espaces en multiples
Chaque mot restant est inséré dans la table d'index individuellement avec le numéro de notice, le code champ et le code sous-champ. On a donc une ligne par mot, par champ, par notice.
Si on reprend l'exemple de la notice N°1 : Le chat botté a été aperçu à l'orée du bois le 12/02/2012 de Charles Perrault, on obtient les index nettoyés
Index du titre |
|
Index de l'auteur |
|
Ce qui donnera dans la table d'index unique en prenant comme convention :
code, sous-code | champ de la notice |
|---|---|
1,1 | Titre, Titre principal |
2,1 | Auteur, Élément rejeté |
2,2 | Auteur, Élément d'entrée |
N° de notice | Code champ | Code sous-champ | Mot | Occurrences |
|---|---|---|---|---|
1 | 1 | 1 | chat | 1 |
1 | 1 | 1 | botte | 1 |
1 | 1 | 1 | ete | 1 |
1 | 1 | 1 | apercu | 1 |
1 | 1 | 1 | oree | 1 |
1 | 1 | 1 | bois | 1 |
1 | 1 | 1 | 12 | 1 |
1 | 1 | 1 | 02 | 1 |
1 | 1 | 1 | 2012 | 1 |
1 | 2 | 1 | charles | 1 |
1 | 2 | 2 | perrault | 1 |
La colonne occurrences représente le nombre de fois où le mot est présent dans le champ. Cela évite de multiplier les entrées dans la table.
La table d'index nettoyé est la table notices_mots_global_index.
Structure de la table d'index exact
De la même manière que pour l'ancienne recherche, les index exacts sont conservés tel quels. Chaque champ d'une notice est associé à un code et un sous code (comme en unimarc !). Pour chaque notice, chaque index exact de chaque champ de notice est inséré dans une table unique d'index, avec le numéro de notice, le code champ et le code sous -champ.
L'index exact de la notice N°1 :
N° de notice | Code champ | Code sous-champ | Index exact |
|---|---|---|---|
1 | 1 | 1 | Le chat botté a été aperçu à l'orée du bois le 12/02/2012. |
1 | 2 | 1 | Charles |
1 | 2 | 2 | Perrault |
La table d'index nettoyé est la table notices_fields_global_index.
Analyse de la saisie
L'analyse de la saisie ne diffère pas. La représentation en arbre est toujours la même.
Principe général de construction de la recherche
De la même manière que l'ancienne recherche, l'arbre est parcouru dans l'ordre de ses termes.
Si le terme est un mot simple, on effectue la recherche dans l'index nettoyé
Si le terme est une branche, on évalue cette branche comme une recherche autonome.
Si le terme est une expression exacte, on effectue la recherche dans l'index non nettoyé
Le résultat de recherche de chaque terme est combiné au précédent selon l'opérateur.
C'est évidemment la génération des requêtes SQL qui va changer.
Pour un terme simple représentant un mot nettoyé, on génère une requête qui recherche dans la table d'index les lignes qui correspondent au mot :
select distinct id_notice from notices_mots_global_index where mot='bois' (le mot distinct signifie identifiants différents, cela évite de récupérer les identifiants en double)
Pour un terme simple représentant une expression exacte, on génère une requête qui recherche dans la table d'index exact les lignes qui correspondent à la phrase :
select distinct id_notice from notices_fields_global_index where value like '%chat botté%'
Chaque terme de chaque branche est lui-même évalué de la même manière.
Le résultat des recherches de chaque terme est stocké dans une table temporaire en mémoire de MySQL, puis on effectue une jointure en fonction des opérateurs entre les termes :
- Pour un
ou: une union entre deux tables temporaires (on met bout à bout les résultats) - Pour un
et: une jointure stricte entre deux tables (on prend les identifiants présents dans les deux tables) - Pour un sauf : une jointure à gauche avec null à droite (on prend les identifiant d'une table non présents dans l'autre)
Le résultat de chaque jointure est lui-même stocké dans une table temporaire et utilisé ensuite pour être combiné avec l'opérateur suivant.
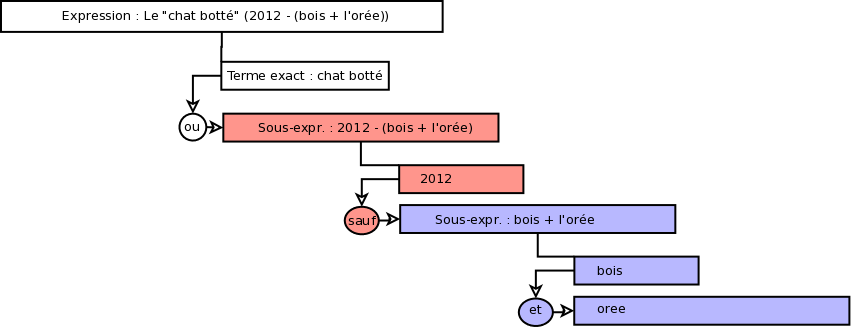
Expression d'origine : Le "chat botté" (2012 - (bois + l'orée))
Terme exact "chat botté" sur le titre :
create temporary table t0 memory (select distinct id_notice from notices_fields_global_index where value like '%chat botté%' and code_champ=1)
Terme nettoyé 2012 sur le titre :
create temporary table t1 memory (select distinct id_notice from notices_mots_global_index where mot='2012' and code_champ=1)
Terme nettoyé bois sur le titre :
create temporary table t2 memory (select distinct id_notice from notices_mots_global_index where mot='bois' and code_champ=1)
Terme nettoyé oree et bois sur le titre :
create temporary table t3 memory (select distinct notices_mots_global_index.id_notice from notices_mots_global_index join t2 on (t2.id_notice=notices_mots_global_index.id_notice) where mot='oree' and code_champ=1
Opérateur sauf entre 2012 et bois + oree
create temporary table t4 memory (select distinct t1.id_notice from t1 left join t3 on (t1.id_notice=t3.id_notice) where t3.id_notice is null
Opérateur ou entre "chat botté" et (2012 et bois + oree)
create temporary table t5 memory (select t0.id_notice from t0 union select t4.id_notice from t4)
Le résultat est dans la table temporaire t5.
L'exemple précédent effectue une recherche sur le titre. Dans chaque requête, le champ est précisé avec la clause code_champ=1. Pour la recherche tous les champs, il suffit d'enlever cette clause ou d'ajouter une clause sur plusieurs codes si on ne veut pas absolument tous les champs : code_champ in (1,2,3, ...). Il est facile ainsi de faire des index agrégés personnels.
Calcul de pertinence
De la même manière que pour l'ancienne recherche, on ne raisonne que sur les mots positifs. On distingue les termes exacts et les termes nettoyés.
- Pour les termes exacts, la pertinence est la somme des tests value='xxx' pour les notices du résultat de recherche dans la table d'index exact (
notices_fields_global_index). - Pour les termes nettoyés, la pertinence est la somme des tests mot='xxx' pour les notices du résultat de recherche dans la table d'index exact (
notices_mots_global_index).
Dans notre exemple :
- Terme nettoyé positif : 2012 (les termes bois et oree ne peuvent être présents)
- Terme exact positif : "chat botté"
Pertinence nettoyée = select mot='2012' from notices_mots_global_index where id_notice in (select id_notice from t5) and code_champ=1
Pertinence exacte = select value like '%chat botté%' from notices_fields_global_index where id_notice in (select id_notice from t5) and code_champ=1
La pertinence totale est la somme des résultats des deux requêtes.
Lors de la construction des tables index, on rajoute une colonne nommée pond avec une pondération associée à chaque champ/sous champ. La pondération est entre 0 et 100. Ainsi, on peut donner plus ou moins d'importance aux différents champs d'une notice.
La pondération associée à chaque champ est précisée dans le fichier XML de PMB : opac_css/includes/indexation/notices/champs_base.xml. Ce fichier décrit les champs et sous champs. Ce fichier est substituable. Chacun peut donc se construire son profil de pondération.
Pour tenir compte de la pondération, il suffit de multiplier le test mot='xxx' par la valeur du champ pond
Dans notre exemple :
Pertinence nettoyée = select (mot='2012')*pond from notices_mots_global_index where id_notice in (select id_notice from t5) and code_champ=1
Pertinence exacte = select (value like '%chat botté%')*pond from notices_fields_global_index where id_notice in (select id_notice from t5) and code_champ=1
Dans la cas d'une recherche sur plusieurs champs, il faut sommer l'ensemble des lignes par champ trouvées, par notice. Les requêtes deviennent donc :(par exemple pour tous les champs)
select sum((mot='2012')*pond) from notices_mots_global_index where id_notice in (select id_notice from t5) group by id_notice
select sum((value like '%chat botté%')*pond) from notices_fields_global_index where id_notice in (select id_notice from t5) group by id_notice
- Un nouveau système de recherche
- Les recherches dans PMB : principes théoriques et applications
- Comment fonctionne le système de recherche jusqu'à la version 3.4
- Principales limitations de la recherche jusqu'en 3.4
- Comment fonctionne le nouveau système de recherche à partir de la version 3.5
- Avantages et inconvénients de la nouvelle recherche
- Implications de la nouvelle recherche dans PMB 3.5
- Annexe : liste des codes champ/sous-champ pour l'indexation
