 Notes techniques concernant la version 3.5 de PMBHiérarchie de section : Les recherches dans PMB : principes théoriques et applications > Avantages et inconvénients de la nouvelle recherche
Notes techniques concernant la version 3.5 de PMBHiérarchie de section : Les recherches dans PMB : principes théoriques et applications > Avantages et inconvénients de la nouvelle rechercheAvantages et inconvénients de la nouvelle recherche
Performances
Avantages
Le principe de base qui justifie ce type de système de recherche est le suivant : bien que la table d'index nettoyé comporte un très grand nombre de lignes (une par mot de chaque champ de chaque notice) par rapport au nombre de notices, la performance est basée sur le fait que le nombre de mots dans une langue est relativement restreint (60 000 environ en français pour le langage courant écrit et oral).
Cela signifie que l'on peut utiliser à plein les possibilités d'indexation et de tri de MySQL. La recherche d'un mot dans 60 000 entrées indexés et triées est quasi-immédiate, et MySQL est capable d'y associer directement les lignes associées.
Nous avons choisi d'utiliser un système de tables temporaires pour combiner les termes car MySQL permet de forcer la création de ces tables en mémoire. Bien que le nombre de requêtes soit beaucoup plus important pour arriver au même résultat, le fait de forcer la création des tables intermédiaires en mémoire permet une performance sans commune mesure avec les jointures traditionnelles.
Cela utilise la mémoire vive du serveur MySQL, mais uniquement avec des identifiants de notice, ce qui n'est pas forcément plus gourmand qu'une jointure traditionnelle qui est susceptible de copier l'ensemble des champs d'une table en mémoire lors d'une requête.
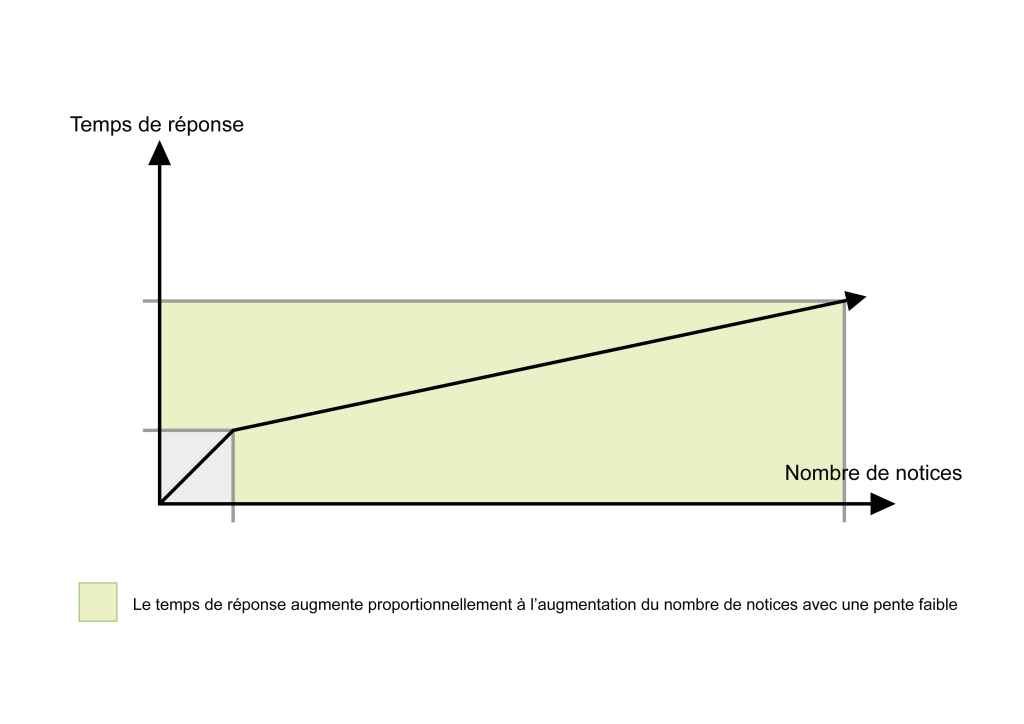
La même recherche a un temps de réponse divisé par 10 sur des bases de l'ordre de 100 000 notices, divisé par 100 sur des bases de l'ordre de 650 000 notices.
En pratique, les temps de recherche augmentent proportionnellement au nombre de notices, mais avec une pente faible. Cela permet de gérer beaucoup plus de notices pour de bons temps de réponse.
Inconvénients
Le principal inconvénient est la taille des tables index. Sur un nombre de notices important, la taille des fichiers qui stockent les données des tables d'index peut être suffisamment importante pour que les performances s'effondrent du fait du système d'exploitation lui même (adressage insuffisant).
Ce problème peut être facilement contourné avec le partitionnement des tables à partir de MySQL 5.1.
Un autre inconvénient réside dans le fait que la création des tables d'index exact ou nettoyé finalement duplique l'intégralité des données liées aux notices.
Ce problème est commun à tous les moteurs d'indexation performants qui, par définition, sont obligés d'analyser et de représenter (et donc de copier !) l'intégralité des données cherchables.
Une troncature avec trop peu de caractères (en général inférieure à 3 caractères) fait s'effondrer les performances :
La recherche ab* donne de mauvais résultats (au delà d'un certain volume de notices). En effet, au delà d'un certain nombre de notices potentiellement concernées par la recherche, MySQL estime qu'il est plus efficace de passer en revue toute la table que d'utiliser ses propres index triés. Si la taille du fichier de données lié à la table est importante, les performances chutent fortement.
Ce problème peut être facilement contourné avec le partitionnement des tables à partir de MySQL 5.1.
Finalement, l'effet de seuil est essentiellement dû à la taille du fichier de données associé aux tables d'index.
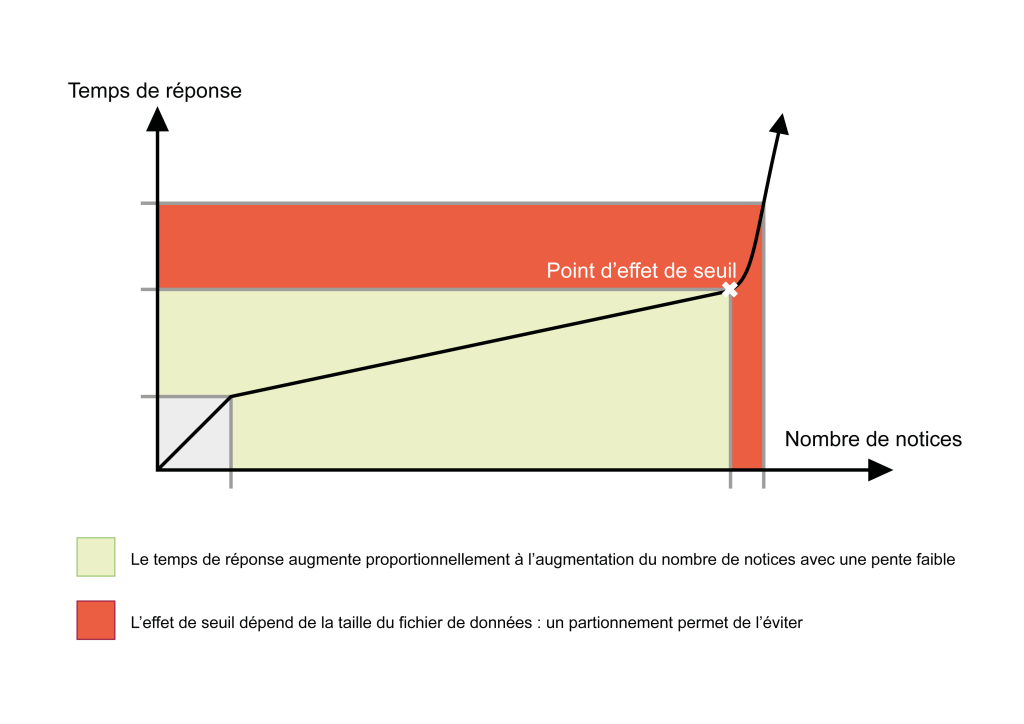
Partitionnement pour limiter l'effet de seuil
A partir de la version 5.1 de MySQL, il est possible pour une grosse table de données de la scinder en plusieurs fichiers. La table est toujours vue comme une table unique dans MySQL, mais elle est physiquement répartie dans plusieurs fichier plus petits.
Ce partitionnement améliore fortement les temps d'accès aux données (et donc les temps de recherche).
On peut choisir d'utiliser le critère de partitionnement que l'on souhaite (un champ, un clé de la table, une expression SQL) et un nombre de partitions. Il vaut mieux partitionner sur les valeurs recherchées (dans le cas de l'index nettoyé, le champ mot par exemple).
Une fois partitionnée, lors d'une recherche sur un mot (tronqué ou non), MySQL détermine quel(s) fichier(s) contient les lignes susceptibles d'avoir ce mot et il ne travaille qu'avec ce(s) fichier(s). On peut ainsi diviser fortement le volume de données manipulées en même temps. Les performances augmentent d'autant.
Une table de 1 000 000 d'enregistrement partitionnée en 20 sur les mots donnera 20 tables de 50 000 lignes. Lors de la recherche d'un mot, si son classement alphabétique ne désigne qu'un seul fichier, MySQL manipulera 50 000 notices au lieu de 1 000 000...
Même si le mot est susceptible d'être présent dans 4 fichiers, cela ne fait toujours que 200 000 lignes à manipuler, soit 5 fois moins que le total.
On évite aussi l'effondrement des performances lié aux mauvaises performances de système d'exploitation qui ouvre un gros fichier.
Selon l'importance de votre base (plus de 50 000 notices), MySQL 5.1 minimum est donc fortement recommandé pour la version 3.5 de PMB.
Autres avantages (présents ou avenir)
Pondérations évoluées
Le schéma des tables d'index présenté au chapitre précédent est une version simplifiée. En réalité, nous avons ajouté la langue du mot et la position du mot dans le champ.
Cela permettra à terme de développer des pondérations plus précises en fonction de la proximité des mots recherchés.
Les comptages de fréquence d'apparition des mots dans les notices sont aussi très faciles a réaliser pour influencer la pondération des termes.
Mise en cache des résultats de recherche
Indépendamment du nouveau système de recherche, nous en avons profité pour mettre en cache les résultats de recherche. Ainsi, après une recherche, lors de la navigation par page, les résultats sont immédiats.
Recherche phonétique
Comme les index sont découpés en mots individuels, il est très facile de faire une comparaison non pas uniquement sur le mot mais sur l'empreinte phonétique du mot recherché et du mot de l'index.
Cette fonctionnalité n'est pas encore développée dans PMB mais est prévue.
Facettes, sémantique et éditions
La mise à plat de toutes les informations des notices dans la table d'index exact permet la présentation par facettes. En effet, il est facile pour un ensemble de notices et pour un choix de champs de rechercher les valeurs distinctes dans des champs et de les afficher sous forme de facette.
La mise à plat permet aussi de faire la recherche de notices qui ont le plus de champs similaires à une notice donnée. Cela permet de proposer des similitudes.
On peut facilement avec cette structure faire des éditions sans bien connaître le modèle de données de PMB. En effet, les valeurs de tous les champs d'une notice sont déjà associées avec les codes de champs/sous-champ dans une table unique.
- Un nouveau système de recherche
- Les recherches dans PMB : principes théoriques et applications
- Comment fonctionne le système de recherche jusqu'à la version 3.4
- Principales limitations de la recherche jusqu'en 3.4
- Comment fonctionne le nouveau système de recherche à partir de la version 3.5
- Avantages et inconvénients de la nouvelle recherche
- Implications de la nouvelle recherche dans PMB 3.5
- Annexe : liste des codes champ/sous-champ pour l'indexation
